需求分析
本次任务的模型有两个输入端,分别是把 16个文档集 和 16 个查询关键词作为输入,在模型内部结构中,两个输入分别进行处理。
- 第一个输入端把 16 个文档集经过预处理 的去 htm 标签、用 jieba 分词器进行中文分词、最后去除文档中的停用词后通过 tf-idf 模型后进行文档权重排序
- 第二个输入端是将查询关键词进行查询处理,分别进行关键词分 词、提升词频、同义词拓展和索引的 idf 权重判断,然后和 处理后的16 个文档集一同进入空间向量模型计算余弦得出 相似度,并把相似度大于 0.5 的文档作为结果输出,同时得 出 if-idf 和 F1 值,搜索结束。
背景知识
词向量
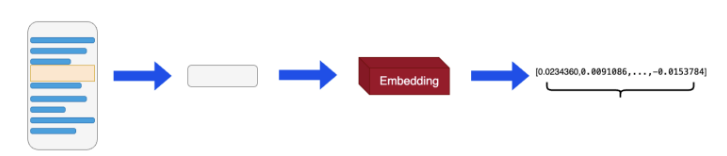
在机器学习和自然语言处理(NLP)中,词向量(Embeddings)是一种将非结构化数据,如单词、句子或者整个文档,转化为实数向量的技术。这些实数向量可以被计算机更好地理解和处理。
嵌入背后的主要想法是,相似或相关的对象在嵌入空间中的距离应该很近。
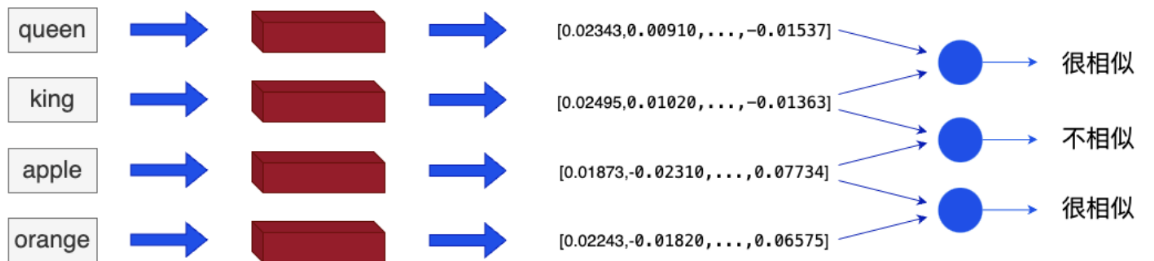
举个例子,我们可以使用词嵌入(word embeddings)来表示文本数据。在词嵌入中,每个单词被转换为一个向量,这个向量捕获了这个单词的语义信息。例如,"ing"和"queen"这两个单词在嵌入空间中的位置将会非常接近,因为它们的含义相似。而"apple"和"orange"也会很接近,因为它们都是水果。而"king"和"apple"这两个单词在嵌入空间中的距离就会比较远,因为它们的含义不同。
TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用于信息检索和文本挖掘的加权技术,用来评估一个词语对于一个文档集合中的某一文档的重要程度。TF-IDF由两部分组成:
- TF(Term Frequency,词频):表示某个词语在文档中出现的频率。如果一个词在文档中出现次数多,说明它对文档的意义更重要。TF的公式通常是词语在文档中出现的次数除以文档总词数。
- IDF(Inverse Document Frequency,逆文档频率):衡量一个词的普遍重要性。如果一个词在很多文档中都出现,则它对区分文档的贡献小;反之,如果一个词只在少数文档中出现,则它具有较高的区分度。IDF的公式通常是文档总数除以包含该词的文档数,然后取对数。
综合起来,TF-IDF的计算公式为:
\text{TF-IDF}(t,d,D) = \text{TF}(t,d) \times \text{IDF}(t,D)其中,(t)代表词语,(d)代表文档,(D)代表文档集合。
文本向量余弦距离
余弦相似度的灵感来自于数学中的余弦定理:
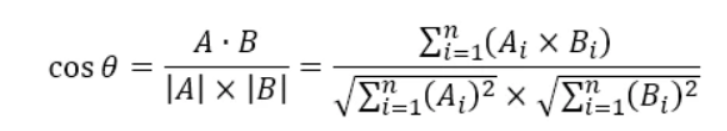
其中,A、B 分别是文本一、文本二对应的 n 维向量。
举例:
文本A是 “一个雨伞”,文本B是 “下雨了开雨伞”,它们的并集是 {一,个,雨,伞,下,了,开},共 7 个字。
若并集中的第 1 个字符在文本一中出现了 n 次,则 A1=n(n=0,1,2……)。
若并集中的第 2 个字符在文本一中出现了 n 次,则 A2=n(n=0,1,2……)。
依此类推,算出 A3、A4、……、A7,B1、B2、……、B7,最终得到:
A=(1,1,1,1,0,0,0)
B=(0,0,2,1,1,1,1)
将 A、B 代入计算公式,得到
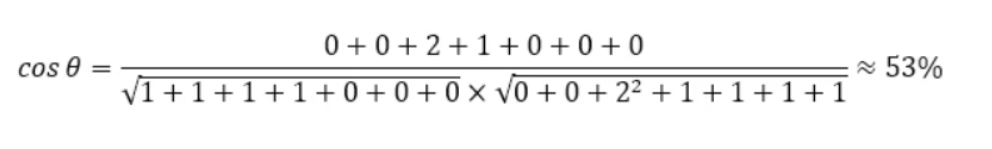
数据介绍-TrainingReleased_CS
在“TrainingReleased_CS”文件夹中有四个子文件夹:
(1)话题(Topics)
关于2个训练话题的描述位于文件moat7-cs-training.xml中。
话题ID与其在此文件中的标识对应如下:
话题ID 文件夹名称 moat7-cs-training.xml中的话题名称
N01 N01 MOAT7-CS-N01
N02 N02 MOAT7-CS-N02
例如,若要查找话题N01的描述,其文件夹名为N01,在moat7-cs-training.xml中寻找话题MOAT7-CS-N01。
(2)STNO_UNICODE
此文件夹包含供系统提取意见的文件。
文档被分割为句子,每个句子被标记为
句子内容。
此文件夹中的文件采用UNICODE编码,并以[文档编号].stno命名。
(3)Annotated_UNICODE
STNO_UNICODE文件夹中的文件经过标注后存放于此。每个文件由三位标注员进行标注。
因此,针对每个话题有三个存放标注文件的子文件夹。
此文件夹中的文件同样采用UNICODE编码,命名方式为[文档编号].stno。
(4)CSV
从Annotated_UNICODE文件夹中的文件提取的答案被写入CSV格式文件中。
此文件夹中的每个CSV文件对应Annotated_UNICODE中一个子文件夹内的答案。
CSV文件中记录的格式如下:
话题ID,文档编号,句子编号,意见ID,语言,持有者,目标,是否有意见表述,是否相关,情感极性
输入端实现过程
第一个输入端:Preprocessing.ipynb
预处理去 html 标签
在STNO-UNICODE中的原始文件,以N01中的文件举例
初始格式为.stno,由于是采用UTF-8编码,因此打开如下所示
可见文件中存在大量的XML(Extensible Markup Language)标签。因此首先需要去除掉XML标签,得到干净的文本数据。
def remove_html_tags(text):
"""Remove html tags from a string"""
clean = re.compile('<.*?>')
return re.sub(clean, '', text)随后,将干净的文本数据写入为.txt后缀的文本文件, 存到Tagsremoved文件夹中:
dir_path_NoXML = os.path.dirname(new_file_path_NoXML)
if not os.path.exists(dir_path_NoXML):
os.makedirs(dir_path_NoXML)
# 写入新的txt文件
with open(new_file_path_NoXML, "w+", encoding='utf-8') as newf_text:
newf_text.write(text_tags_removed)
用 jieba 分词器进行中文分词
for file in filenames:
fp = os.path.join('STNO-UNICODE', dir_N, file)
with open(fp, 'rb') as f:
raw_data = f.read()
# chardet 检测文件编码
detected = chardet.detect(raw_data)
encoding = detected['encoding']
with open(fp, encoding=encoding) as f:
raw_text = f.read()
text_tags_removed = remove_html_tags(raw_text)
tags = jieba.analyse.extract_tags(text_tags_removed)写入到ProcessedData文件夹中:
去除文档中的停用词
定义stop_words.txt, 写入停用词如0001,0002,0003等,排除干扰
# 将停用词表从文件读出,并切分成一个数组备用
stopWords_dic = open('stop_words.txt','r',encoding='utf-8') # 从文件中读入停用词
stopWords_content = stopWords_dic.read()
stopWords_list = stopWords_content.splitlines() # 转为list备用
stopWords_dic.close()通过 tf-idf 模型后进行文档权重排序
# corpus通常指的是一个大型的、结构化的文本集合,用于研究语言模式、频率统计或其他分析。
# 这些文本可能包括书籍、新闻文章、
# 用来暂时将切词后的文本存储起来
corpus=[]
def batch_get_tfidf(filepath_aftercut):
global corpus
#使用sklearn库函数求tfidf需要输入一个列表(list)我们把它定义为——corpus
files=os.listdir(filepath_aftercut)#遍历已经cut完的文件
for file_name in files:
with open(filepath_aftercut+"//"+file_name,'r',encoding='utf-8') as fx:
fres=fx.read()
#把一篇文章(str)作为一个元素加入列表
corpus.append(fres)
#将分词后的文本加入到corpus中
batch_get_tfidf(aftercut_path)文档权重排序:
tfidf_vectorizer = TfidfVectorizer(stop_words=stopWords_list)
tfidf_matrix = tfidf_vectorizer.fit_transform(corpus)写入TF-IDF 值到文件:
# 保存 TF-IDF 值到文件
with open("tfidf_scores.txt", "w", encoding="UTF-8") as f:
feature_names = tfidf_vectorizer.get_feature_names_out()
for i, filename in enumerate(filenames):
f.write(f"=== {filename} ===\n")
feature_index = tfidf_matrix[i, :].nonzero()[1]
tfidf_scores = zip(
feature_index, [tfidf_matrix[i, x] for x in feature_index]
)
for word_index, score in tfidf_scores:
f.write(f"{feature_names[word_index]}: {score}\n")
f.write("\n")
return tfidf_vectorizer, tfidf_matrix, filenames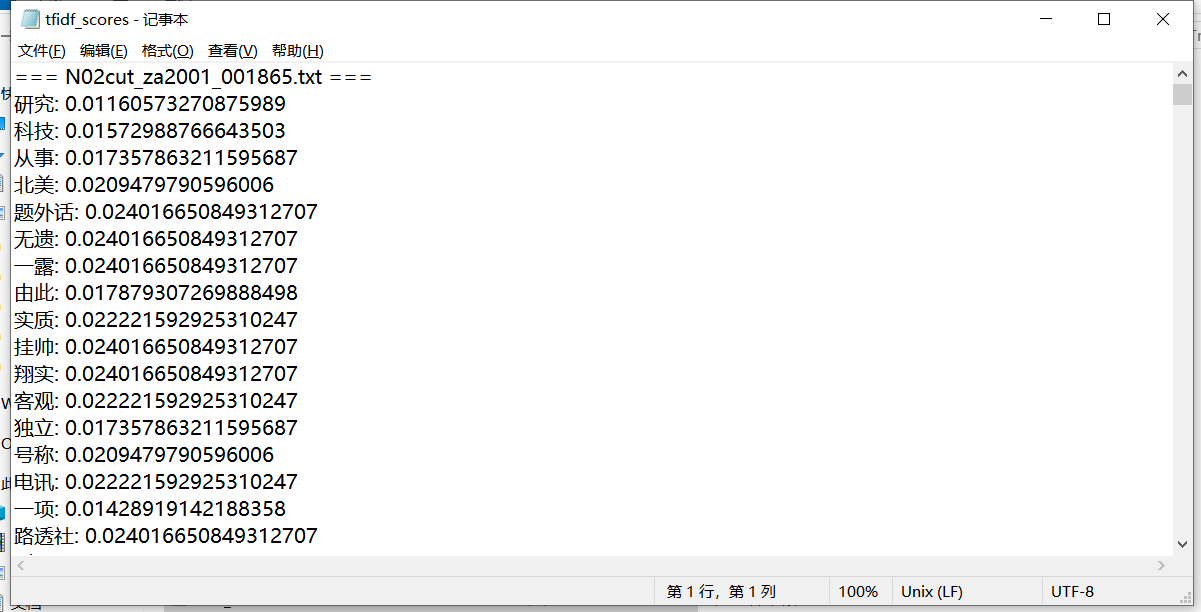
第二个输入端: main.ipynb
关键词分词、索引的idf 权重判断
# ① 用户输入查询词,将查询词转化为向量形式
query = input("请输入查询词:")
query_cut = ' '.join(jieba.cut(query))
query_vector = vector.transform([query_cut])
query_tfidf = tfidf_vectorizer.transform([query_cut])
处理后的16个文档集一同进入空间向量模型
文档集放入内存中,用变量corpus存储:
# corpus通常指的是一个大型的、结构化的文本集合,用于研究语言模式、频率统计或其他分析。
# 这些文本可能包括书籍、新闻文章、
# 用来暂时将切词后的文本存储起来
corpus=[]
def batch_get_tfidf(filepath_aftercut):
global corpus
#使用sklearn库函数求tfidf需要输入一个列表(list)我们把它定义为——corpus
files=os.listdir(filepath_aftercut)#遍历已经cut完的文件
for file_name in files:
with open(filepath_aftercut+"//"+file_name,'r',encoding='utf-8') as fx:
fres=fx.read()
#把一篇文章(str)作为一个元素加入列表
corpus.append(fres)
#将分词后的文本加入到corpus中
batch_get_tfidf(aftercut_path)文本向量化:
tfidf_vectorizer = TfidfVectorizer(stop_words=stopWords_list)
tfidf_matrix = tfidf_vectorizer.fit_transform(corpus)计算余弦得出相似度:
# 定义返回最相关的几篇文档
top_k = 5
query_tfidf = tfidf_vectorizer.transform([query])
similarities = cosine_similarity(query_tfidf, tfidf_matrix)[0]
sorted_indices = similarities.argsort()[::-1]
sorted_indices = sorted_indices[:top_k]输出最相关的文档:
# 结果输出
def print_corpus_by_indices(sorted_indices, corpus):
global index
output = [] # 用于记录全文输出
reltheme = [] # 用于记录含有三个字符的数组
for fffx in sorted_indices:
if fffx < len(corpus):
text = corpus[fffx]
if len(text) >= 3:
reltheme.append(text[:3])
output.append(text) # 将全文添加到output中
return output, reltheme
# 调用函数并将结果存储在output和reltheme中
output, reltheme = print_corpus_by_indices(sorted_indices, corpus)
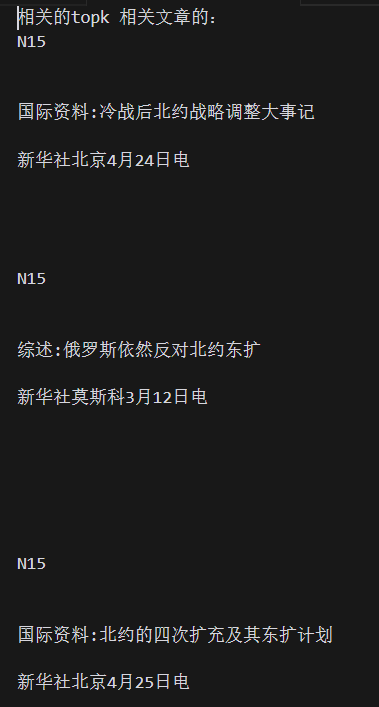
print("相关的topk 相关文章的:")
for text in output:
# 打印text前30个字
print(text.replace(" ", "")[:40])
print("输出的文章分别属于哪个主题/含有三个字符的数组:")
for text in reltheme:
print(text)输出Top-K文章内容:以查询词北约为例
precision、f1_score、F1 值
以下代码来自tf-idf-main.ipynb
calculate_prf:
def calculate_prf(query_results_in, ground_truth):
query_results = [filename.split(".")[0] for filename in query_results_in]
print(query_results)
if len(query_results) == 0:
return 0, 0, 0
true_positives = len(set(query_results) & set(ground_truth))
precision = true_positives / len(query_results)
recall = true_positives / len(ground_truth)
if precision == 0 and recall == 0:
f1_score = 0
else:
f1_score = (2 * precision * recall) / (precision + recall)
return precision, recall, f1_score加载参考文本集:
def load_ground_truth(ground_truth_folder):
ground_truth = []
root = "aftercut"
for filename in os.listdir(os.path.join(root, ground_truth_folder)):
name, ext = os.path.splitext(filename)
ground_truth.append(name)
return ground_truth
ground_truth_folder = ""
ground_truth = load_ground_truth(ground_truth_folder)打印准确率、召回率、F1 score:
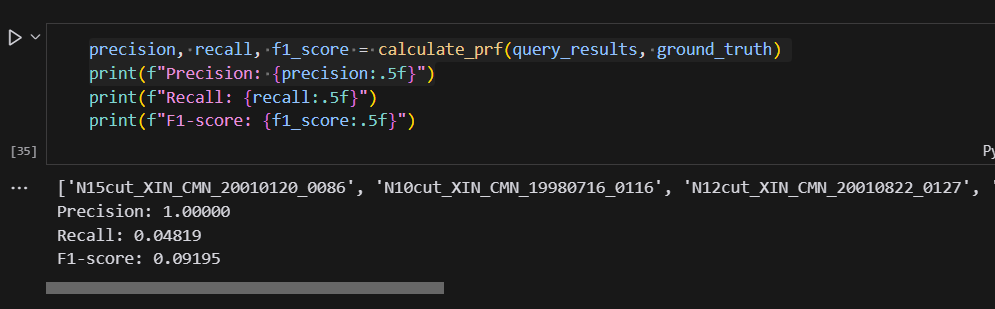
总结与感悟:
完成这个大作业是一个综合性的学习过程,涉及到了信息检索、自然语言处理、机器学习等多个领域的知识,不仅提升了我的技术能力,也加深了我对团队合作重要性的理解。以下是我从几个不同角度的总结与感悟:
数学模型应用
- TF-IDF:在处理文档集时,使用TF-IDF模型对文档中的词语进行了加权,这一过程深刻体现了如何利用数学统计方法来衡量词语在文档中的重要性。它教会我如何在大量文本数据中筛选出最具代表性的词汇,这对于理解和区分文档主题至关重要。
- 余弦相似度:在计算查询关键词与文档集的相似度时,采用余弦相似度是一个高效且直观的方法。通过这个过程,我不仅理解了如何在高维向量空间中衡量两个向量的夹角余弦值以表示它们之间的相似程度,还学会了如何在实际问题中有效地应用这种数学概念。
- Precision、Recall与F1值:除了直接的相似度计算,Precision和Recall值对于提升搜索的相关性和准确性尤为重要。而F1值作为评估模型性能的一个重要指标,让我意识到在追求高召回率的同时,也需要保证精确率,以达到两者之间的平衡。
代码能力提升
- 编程技巧:实现上述流程需要熟练掌握Python编程,特别是在文本处理和数值计算库(如jieba、numpy、scikit-learn等)的应用上。这个过程中,我不仅提高了编写高效、可读性强的代码的能力,还学会了如何调试和优化代码,确保模型的运行效率。
- 模块化编程:面对复杂的任务,我学会了将整个项目拆分成若干个小模块(如预处理、分词、相似度计算等),每个模块负责一部分功能,这不仅提高了代码的可维护性,也便于团队成员之间的协作。
团队合作经验
- 沟通协调:在这个项目中,有效沟通是成功的关键。我们团队需要定期讨论进度、遇到的问题以及解决方案,这锻炼了我的沟通技巧和团队协作能力。通过明确分工和责任,确保了每个人都能发挥所长,高效推进项目。
- 协同工作:使用版本控制系统(如Git)进行代码管理,确保了团队成员可以同时工作而不至于造成冲突。这个过程中,我学会了如何合理安排合并代码的时间点,以及解决代码冲突的方法,这些都是团队开发中不可或缺的技能。
- 相互学习:团队成员来自不同的背景,每个人都有自己的强项。通过共同解决问题,我不仅从他人那里学到了新知识,也分享了自己的见解,这种互帮互助的氛围极大地促进了个人成长。


0 条评论