2024/06/01 学院断电,预防式关机
学院于2024/06/01 凌晨0/00分断电约30分钟,为避免正在运行中的容器丢失数据,采用远程连接到各node的方式进行手动shutdown。
次日上午来电后再前往机房手动开启机器,检查各设备运行情况。
目前一切正常。
tips:似乎服务器bios中有设置断电后突然来电,自动恢复运行。是否如此有待验证
2024/06/28 Node5 CUDA驱动自动更新导致版本不匹配
报告人:李挺
问题描述:CUDA驱动由原本的535.171.04自动更新至535.183,导致Nvidia-smi无法正常工作。CUDA驱动与显卡驱动版本不匹配
解决思路:cat /var/log/dpkg.log|grep nvidia 查看日志,发现是系统于早上6点自动联网更新驱动
解决办法:手动关闭ubuntu的自动更新功能。根据CSDN经验,重启后CUDA会自动回退至于显卡驱动匹配的版本
2024/07/15 Node5存储空间不足,K8S无法调度pod在其上工作
报告人:李义
问题描述:
日常巡视检查中,发现Ollama和One API无法被调度至node5上。检查 kubectl describe node server-node5,发现节点 server-node5 由于磁盘压力过大而驱逐了该 Pod。
Node5被标记污点:Taints: node.kubernetes.io/disk-pressure:NoSchedule
解决思路:
df -h/ du -h 查看node5各挂载盘使用情况。经检查后发现是已毕业的师兄们存放了大量数据集,以及长期未清理系统缓存所致。
解决办法:清除了施明杰的大容量数据集。手动清理缓存:https://blog.csdn.net/ye1223/article/details/88607973
目前node5的存储空间使用量从92%降低至47%。成功恢复运行
2024/07/16 node4的flannel出现故障,seafile无法正常使用
问题描述:日常巡视中,发现kubectl get pods -A中,用于运行seafile的Pod被调度至node4节点,但反复出现crashbackoff的状态,即运行一段时间后出现故障,重启后仍存在,反复崩溃的状态
解决思路:查看flannel插件和kubelet-proxy两个pod的日志,发现master的调度命令不能准确传达至node4。初步判定是flannel插件出现故障。将删除插件后,重新安装,重新将node4加入到集群中
解决进度:已解决
2024/08/05 Ollama支持LLama3.1;新用户注册管理
http://172.22.164.35:30012/ Ollama管理
- 拉取了最新LLama3.1 8b模型
- 新增用户的注册及审批
- 管理员文档整理
2024/08/10 Node0重启路由表丢失及找回;Kubelet故障
问题描述:重启node0网关服务器后,iptables路由规则全部丢失,无法连接到各容器及网络服务
解决思路:一开始想根据shell History记录来重新添加路由规则,但这样容易疏漏,且k8s的路由规则也会丢失,费时费力
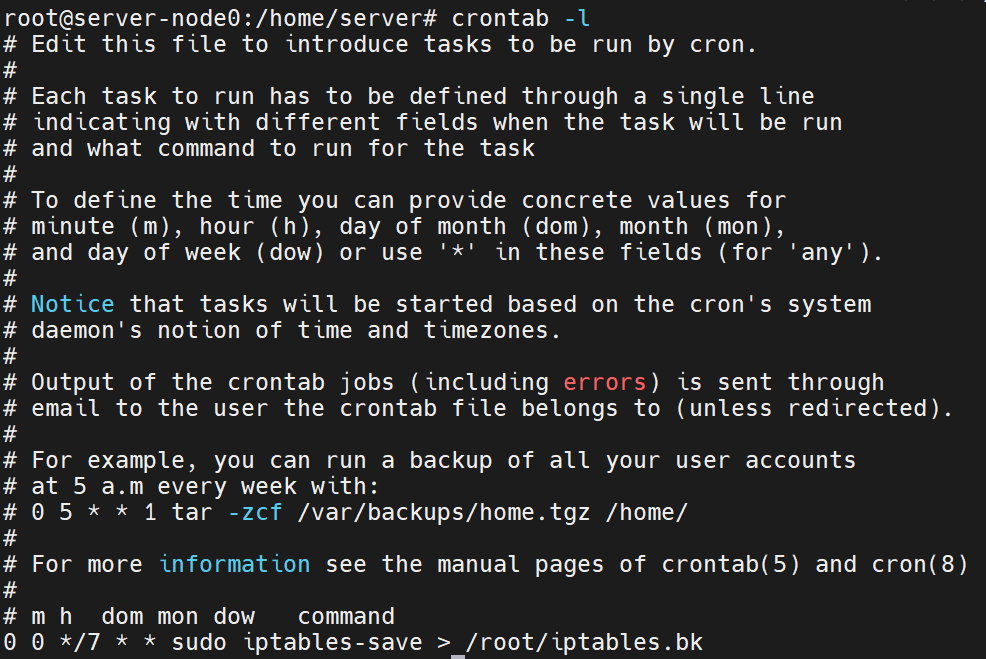
解决办法:询问潘梦源师兄得知node0有设置定时备份iptables,位于/root/iptables.bk。
具体恢复方法参考博客:https://www.cnblogs.com/crxis/p/9120369.html
恢复后,各容器恢复了正常运行,但网络服务如Ollama等无法访问。
kubectl get nodes后发现,node0处于NotReady状态。
Node NotReady故障排查:https://www.cnblogs.com/fenjyang/p/14417494.html
最开始考虑是忘记关闭swap分区,后发现是node0 kubelet出现故障,无法向master发送ready的消息
随后journalctl -xefu kubelet查看日志,发现是docker的daemon进程启动失败
找了N久教程,发现是/etc/docker/daemon.json少了一个标点符号。。。。。导致docker启动失败
更正后,重启daemon,重启docker,重启kubelet,检查集群,各节点都Ready;网络服务均顺畅运行。
定时保存iptables:crontab命令,如下图所示:

0 条评论